Jiří Pavela: Library for Profiling of Data Structures of C/C++ Programs
| Thesis Detail | Institution site |
| Thesis Download | Thesis Download |
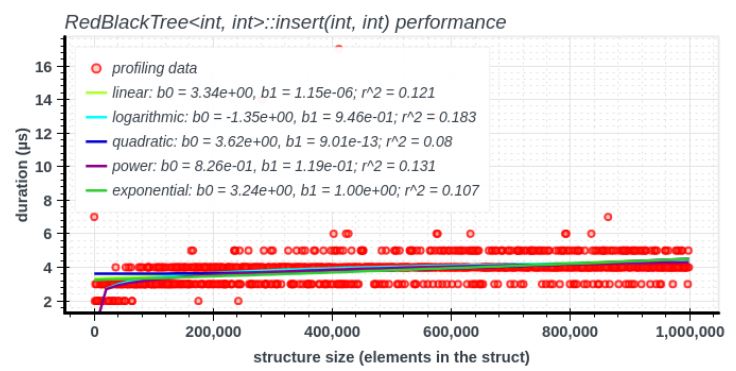
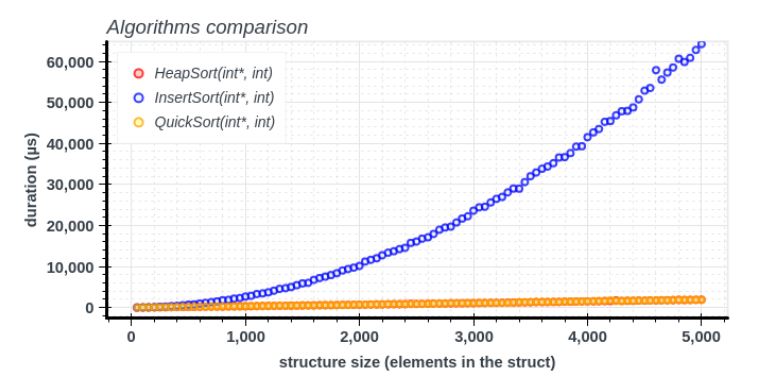
The goal of this thesis was to create a time profiler of C/C++ programs together with tracking sizes of advanced data structures (such as linked lists or skip lists). The collected data was postprocessed using regression analysis to infer mathematical models (which modeled runtime of functions based on sizes of underlying structures). The results were visualized using scatter plots.
Abstract
Performance bugs may greatly affect the quality of the system being developed and even cause irreversible damage in some critical sectors. Hence profiling - one of the currently most widespread technique of performance analysis - is usually applied to find the bugs. However, most of the current solutions commonly lack comprehensible graphical outputs and detailed analysis of algorithms in regard to their complexity. This thesis introduces a novel profiling tool which focuses on automatic estimation of complexity of dynamic data structures. The proposed approach collects statistical data out of program runs and uses regression analysis to find the most accurate model serving as an estimate of algorithmic complexity. The resulting prototype was subjected to a series of experiments that evaluate the accuracy of the results, demonstrate practical uses and illustrate the graphical output of the tool.